
View more presentations from Terrafx9.
miércoles, 18 de enero de 2012
martes, 10 de enero de 2012
Administración remota en Windows
En Windows, al igual que en Linux se utiliza el acceso en modo texto, para ello tenemos los mismos protocolos (SSH y Telnet). También existen herramientas para hacerlo de manera gráfica tales como putty de la cual pondré un videotutorial explicativo de todo el proceso.
Un escritorio remoto es una tecnología que permite a un usuario trabajar en una computadora a través de su escritorio gráfico desde otro terminal ubicado en otro lugar.
Ahora vamos a centrarnos en el procedimiento durante los diferentes sistemas operativos de windows, en el siguiente ejemplo se explica el procedimiento en windows 7:
Ahora vamos a ver la configuración y funcionamiento sobre windows xp:
Protocolos de acceso remoto y puertos implicados:
Protocolo TCP y puerto 3389
Herramientas gráficas externas para la administración remota:
Tales como: putty, Teamviewer, UltraVNC...
Putty
UltraVNC
TeamViewer
Fuentes:
Administración remota en GNU/Linux
Voy a explicar el acceso sistema en modo texto mediante dos servicios distintos: SSH y telnet
SSH
El servidor de shell seguro o SSH (Secure SHell) es un servicio que permite que un usuario acceda de forma remota a un sistema Linux pero con la particularidad de que las comunicaciones entre el cliente y servidor viajan encriptadas desde el primer momento de forma que si un usuario malintencionado intercepta los paquetes de datos entre el cliente y el servidor, será muy dificil que pueda extraer la información. Se recomienda no utilizar nunca telnet y utilizar ssh en su lugar ya que es mucho más seguro.
Para instalar el servidor y el cliente ssh debemos instalar mediante apt-get el paquete ssh que contiene tanto la aplicación servidora como la aplicación cliente:
root@cnice-desktop:# apt-get install ssh
Los archivos de configuración son:
• /etc/ssh/ssh_config: Archivo de configuración del cliente ssh
• /etc/ssh/sshd_config: Archivo de configuración del servidor ssh
En este último fichero, podremos configurar algunas opciones como son el puerto, por defecto es el 22, el cual, podremos cambiar para mejorar la seguridad ya que hay scripts que atacan directamente al puerto 22 y podría realizar un ataque para acceder a nuestro sistema. También podremos cambiar opciones de la autenticación tales como el tiempo que tendrá el usuario remoto para hacer login en la máquina. También podremos permitir hacer o no login con el usuario "root" así como denegar aquellas máquinas que no queremos que accedan vía SSH.
Después para que los cambios se queden reflejados deberemos reiniciar el servicio con la siguiente orden:
• /etc/init.d/ssh restart: Script para reiniciar el servicio ssh
Ejemplo: Mi PC de sobremesa está en la ip 192.168.1.73 y el puerto SSH que tengo para el mismo es el 4884. La cuenta que voy a usar para conectarme es “fran”, así que para conectar desde mi PC de sobremesa a otro pc de sobremesa que tengo sería:
$ ssh -p 4884 fran@192.168.1.73
Tras esto me pedirá la contraseña:
fran@192.168.1.73's password:
La introducimos y tras un texto de “bienvenida” veremos que nuestro prompt ha cambiado a “nombre_cuenta@nombre_maquina”. Mi otro pc de sobremesa se llama maquinapc, así pues mi prompt es:
fran@maquinapc:~$
Una vez accedemos ya podremos llevar a cabo acciones como copiar, eliminar... archivos de la máquina a la que nos hemos conectado, eso sí, según los privilegios que tenga la cuenta con la que nos hemos conectado.
TELNET
El protocolo Telnet (Telecommunicating Networks) permite abrir un shell en una máquina remota. Este procolo se implementa con arquitectura cliente-servidor, por lo que necesita:
Un servidor Telnet que se esté ejecutando en la máquina remota, y que por defecto, estará escuchando en el puerto 23 TCP.
Un cliente Telnet que nos permita conectarnos al servidor emulando un terminal que se encontrase físicamente conectado a él.
El comando telnet (paquete telnet) es un cliente Telnet. Su sintaxis es la siguiente:
$ telnet <direccion_host> [puerto]
<direccion_host> IP o nombre de la máquina remota.
[puerto] por defecto utiliza el puerto 23 TCP.
ESCRITORIO REMOTO
A continuación dejo un videotutorial del procedimiento para establecer escritorio remoto GNU/Linux:
PROTOCOLOS DE ACCESO REMOTO Y PUERTOS IMPLICADOS
Los dos servicios anteriormente mencionados se basan en TCP/IP y los puertos implicados son los siguientes:
SSH: TCP/IP - 22/TCP
Telnet: TCP/IP - 23/TCP
HERRAMIENTAS GRAFICAS EXTERNAS PARA LA ADMINISTRACION REMOTA
VINO
Ubuntu viene con un sistema de administración remota gráfica ya instalado. Se llama Vino y no es más que un servidor del conocido VNC. No es un sistema seguro (la información no viaja encriptada) y es relativamente lento, aunque no en exceso. Cabe hacer mención también de que el uso de dicha herramienta está más orientado a acceso remoto que a administración remota.
Una vez descrita la herramienta, vamos a proceder a la configuración de VINO, para ello vamos a: “Sistema > Preferencias > Escritorio remoto” y se nos abrirá la ventana de configuración de Vino:

• Permitir a otros usuarios ver mi escritorio: Habilita/deshabilita la administración remota.
• Permitir a otros usuarios controlar tu escritorio: Permite -o no- que el usuario que se conecte a ti pueda controlar el equipo. La deshabilitación tiene sentido por ejemplo si lo que queremos es simplemente mostrar algo a alguien, en lugar de hacer una captura, subirla y pasarle la dirección.
• Pedir confirmación: Es otro método de seguridad para intentar evitar que nadie conecte a tu equipo sin previo consentimiento. Obviamente alguien debe estar delante del ordenador remoto para permitir el acceso. Se informará del siguiente modo:

Requerir que el usuario introduzca una contraseña: Otro nivel de seguridad que se puede combinar con la anterior -o no-. Cualquiera que pretenda acceder a tu escritorio deberá introducir previamente una contraseña para validar el acceso.
Una vez haya alguien conecte a tu sistema, se informará de ello mediante un mensaje emergente. Además desde ese instante y hasta que finalice la conexión permanecerá un icono en el panel, en la zona del reloj:

Si por cualquier circunstancia deseas echar a alguien, puedes seleccionar a quién, o a todos. Para ello tan sólo tienes que hacer click derecho sobre el icono que se ve en la imagen superior y elegir la opción deseada:

A continuación dejo un video sobre VINO:
FREE NX
Es un novedoso sistema de acceso a escritorios remotos totalmente libre, el cual he decidido poner un video explicativo de la configuración y funcionamiento
WEBMIN
Webmin es una herramienta de configuración de sistemas accesible vía web para OpenSolaris, GNU/Linux y otros sistemas Unix. Webmin es una interfase basada en Web que permite la Administración de Sistemas Unix. La idea general de Webmin es poner de forma accesible la configuración de la mayoría de programas/servicios que se usan normalmente en Unix (Linux, etc), de modo que todo se logra mediante formularios Webs, pero a su vez, podemos editar los archivos de configuración en modo editor de texto.
Es una herramienta con interfaz web para la administración de sistemas Linux e incluye un servidor web que funciona con SSL (protocolo HTTPS), por lo que permite la administración remota segura de un servidor.
Tiene estructura modular, disponiendo de módulos que permiten administrar gran cantidad de aspectos del sistema: red, servidores, hardware, archivos, etc., siendo su manejo muy intuitivo. Por todo ello, es una herramienta muy utilizada y recomendable para la administración remota segura de máquinas Linux.
Con él se pueden configurar aspectos internos de muchos sistemas operativos, como usuarios, cuotas de espacio, servicios, archivos de configuración, apagado del equipo, etcétera, así como modificar y controlar muchas aplicaciones libres, como el servidor web Apache, PHP, MySQL, DNS, Samba, DHCP, entre otros.
A continuación, pongo un videotutorial sobre la instalación de esta herramienta gráfica en un sistema operativo Debian y primeros pasos a seguir para administrar de forma remota y segura múltitud de servicios:
FUENTES:
http://www.ite.educacion.es/formacion/materiales/85/cd/REDES_LINUX/otro/Instalacion_de_servidor_de_shell_seguro.html
http://tecnoloxiaxa.blogspot.com/2008/09/cmo-instalar-servidor-ssh-en-ubuntu.html
http://www.estrellateyarde.org/discover/servidores/servidores-basicos/telnet-en-linux/shell-remoto-con-telnet-en-linux
http://tuxpepino.wordpress.com/2007/05/11/ssh-el-dios-de-la-administracion-remota/
sábado, 3 de diciembre de 2011
martes, 29 de noviembre de 2011
Automatización de Tareas
¿Qué es la automatización de tareas? Ventajas.
La automatización consiste en la realización de tareas o acciones que se realizan de forma automática y con cierta periodicidad en un nuestro sistema informático. Existen métodos para la automatización como la programación simple, los macros, los intérpretes y las bombas lógicas, incluso los virus informáticos se podrían considerar también un método para la automatización de tareas. Presenta diversos beneficios o ventajas tales como:
-Incremento de la productividad
-Control sobre el sistema
-Reducción de inventario
-Flexibilidad
-Reducción de costes
Planificación de tareas en sistemas UNIX. Comandos y herramientas gráficas.
En sistemas UNIX se pueden automatizar las tareas del sistema mediante el uso de dos comandos:
CRON
La función básica de cron es la de ejecutar tareas programadas para un determinado momento, y por un usuario con los privilegios necesarios para poder programarlas.
Los ficheros más importantes implicados en el funcionamiento de servicio “cron” son:
-el propio demonio de funcionamiento: crond
-el fichero de configuración (disponible para root): /etc/crontab
-el fichero de inicio y parada del demonio: /etc/init.d/cron
-la orden para la programación de tareas (disponible para los usuarios con suficientes privilegios): crontab
-el sistema de informes (logs) típico de los sistemas GNU/Linux: /var/log/cron
El fichero /etc/crontab está estructurado por líneas, cada una de las cuales contiene una tarea programada, según el siguiente formato:
# minuto hora dia mes dia_semana usuario orden_a_ejecutar
AT
La utilidad “at” se utiliza para programar una tarea que se llevará a cabo en un momento determinado, y no se volverá a ejecutar. La sintaxis de dicho comando sería del siguiente modo
(hora:minuto (dia.mes.año)) + la acción que queramos que el sistema realice en ese momento determinado
Existen varios servicios para programar tareas automáticas, uno de los más comunes que podemos encontrar es webmin que además de servir para la automatización sirve para proporcionar servicio DHCP, DNS,etc.
Una vez instalado para ejecutarlo no tendríamos más que poner en la barra de nuestro navegador: http://localhost:10000 y ya podemos empezar con la automatización de tareas en dicho programa.
Podemos encontrar más herramientas gráficas tales como Gcrontab, gat0 o Scheduled Taks
Planificación de tareas en Windows 2003/2008 Server. Comandos y herramientas gráficas.
Tanto en Windows 2003 como un 2008 existe una utilidad llamada “Programador de tareas” que viene por defecto en el sistema cuando instalamos el S.O, aunque si tenemos cualquier tipo de duda acerca de su utilización simplemente acudiremos al sistema de ayuda de Windows donde se encuentran bien documentados todos los detalles acerca de esta utilidad del sistema.
También podemos recurrir a ciertos programas tales como BackUpTime que nos permitirá automatizar una cantidad considerable de tareas del sistema.
A continuación muestro un tutorial muy útil de automatización basado en BackUpTime:
Conceptos Aclaratorios:
-Bombas lógicas:
-Bombas lógicas:
Las bombas lógicas son piezas de código de programa que se activan en un momento predeterminado, como por ejemplo, al llegar una fecha en particular, al ejecutar un comando o con cualquier otro evento del sistema.
Por lo tanto, este tipo de virus se puede activar en un momento específico en varios equipos al mismo tiempo. Las bombas lógicas se utilizan para lanzar ataques de denegación de servicio al sobrepasar la capacidad de red de un sitio Web, un servicio en línea o una compañía.
-Macro:
Su uso elimina la realización de tareas repetitivas, automatizándolas. Básicamente, se trata de un grupo de comandos de una aplicación, organizados según un determinado juego de instrucciones y cuya ejecución puede ser pedida de una sola vez para realizar la función que se desea.
-Macro:
Su uso elimina la realización de tareas repetitivas, automatizándolas. Básicamente, se trata de un grupo de comandos de una aplicación, organizados según un determinado juego de instrucciones y cuya ejecución puede ser pedida de una sola vez para realizar la función que se desea.
Bibliografía:
lunes, 21 de noviembre de 2011
jueves, 17 de noviembre de 2011
Internet Information Services (IIS)
Internet Information Services o IIS es un servidor web y un conjunto de servicios para el sistema operativo Microsoft Windows. Originalmente era parte del Option Pack para Windows NT. Luego fue integrado en otros sistemas operativos de Microsoft destinados a ofrecer servicios, como Windows 2000 o Windows Server 2003
Este servicio convierte a una PC en un servidor web para Internet, es decir, que en las computadoras que tienen este servicio instalado se pueden publicar páginas web tanto local como remotamente.Los servicios de Internet Information Services proporcionan las herramientas y funciones necesarias para administrar de forma sencilla un servidor web seguro.
La creación de un pequeño espacio web la he realizado en windows 2003 server
Instalación de IIS
Nos vamos a Inicio/Panel de Control/ Agregar o quitar programas, una vez estemos aquí le damos a Agregar o quitar componentes de Windows /servidores de aplicaciones y por ultimo pulsamos sobre “Instalar Internet Information Services (IIS) en caso de que no esté instalado por defecto.


Acto seguido vamos a Inicio/Herramientas administrativas y finalmente accedemos al administrador de
Internet Information Services (ISS)

Una vez mostrada la interfaz gráfica vamos a proceder a la creación de un pequeño espacio web personalizado. Para ello nos vamos a la ruta C:\Inetpub\wwwroot y vamos a modificar el archivo .htm que hay por defecto en su interior (que es el como el index que nos solemos encontrar en los sistemas como Ubuntu)

Una vez terminada la modificación nos metemos como localhost en la barra de direcciones de nuestro navegador Internet Explorer y nos sale nuestro espacio web personalizado.

Similitudes, diferencias y valoración personal
- IIS es un servicio propietario mientras que Apache es totalmente libre.
- ISS solamente se puede utilizar con windows, en cambio apache es multiplataforma y es válido tanto para sistemas basados en windows como en unix.
- IIS a pesar de tener una interfaz gráfica más agradable a la vista, parece que está un poco limitado en cuanto a personalización, funcionabilidad y demás... personalmente prefiero apache debido a que podemos configurar todos los archivos de sus respectivos módulos y de esa forma asegurarnos de que estamos haciendo bien nuestro trabajo, con IIS es posible que se puedan cometer fallos por ser un sistema tan automatizado.
Comando TOP
El comando TOP muestra a tiempo real un listado de los procesos que se están ejecutando en el sistema, especificando además el % de Cpu y Memoria que están utilizando, sus IDs, usuarios que lo están ejecutando, etc.
La salida por pantalla de Top, puede dividirse en dos partes, la “cabecera” el Uptime del servidor, nº de usuarios conectados y load average. En la siguiente línea podemos ver el nº de procesos ejecutandose en el sistema, así como el uso de disco, memoria y cpus.
Posteriormente podemos observar un listado de procesos, que pueden ser ordenados por uso de cpu o memoria. Este listado, muestra varios detalles de cada uno de los procesos, como pueden ser el PID de proceso, usuario que lo ejecuta, %cpu y memoria que consume, comando que está ejecutando o tiempo de ejecución del proceso entre otros.

No obstante cada vez que tengamos que consultar algo acerca del comando Top siempre podemos hacer un "man top"
Las opciones del comando TOP son las siguientes:
TOP -C -->Para visualizar la línea de comandos completa de cada proceso, activado mostrará las rutas completas, mientras que desactivandolo solo muestra el nombre del programa

TOP -D --> Intervalo de actualización y refresco, podemos asignarle un valor numérico (segundos) que determinará cada cuanto actualice la información.
TOP -U --> Monitorizar solamente los procesos de un determinado UID.
TOP -P --> Monitorizar solamente los ID de procesos especificados Ej: Top -P993 -P1909 ( de esta forma solo se mostrarian los dos procesos por pantalla)

TOP -N --> Especificaremos el nº de veces que actualizará hasta que finalice la ejecución de Top.
Ejemplo --> top -n9 (Refrescará la información nueve veces y finalizará la ejecución de TOP)
La salida por pantalla de Top, puede dividirse en dos partes, la “cabecera” el Uptime del servidor, nº de usuarios conectados y load average. En la siguiente línea podemos ver el nº de procesos ejecutandose en el sistema, así como el uso de disco, memoria y cpus.
Posteriormente podemos observar un listado de procesos, que pueden ser ordenados por uso de cpu o memoria. Este listado, muestra varios detalles de cada uno de los procesos, como pueden ser el PID de proceso, usuario que lo ejecuta, %cpu y memoria que consume, comando que está ejecutando o tiempo de ejecución del proceso entre otros.

No obstante cada vez que tengamos que consultar algo acerca del comando Top siempre podemos hacer un "man top"
Las opciones del comando TOP son las siguientes:
TOP -C -->Para visualizar la línea de comandos completa de cada proceso, activado mostrará las rutas completas, mientras que desactivandolo solo muestra el nombre del programa
TOP -U --> Monitorizar solamente los procesos de un determinado UID.
TOP -P --> Monitorizar solamente los ID de procesos especificados Ej: Top -P993 -P1909 ( de esta forma solo se mostrarian los dos procesos por pantalla)
TOP -N --> Especificaremos el nº de veces que actualizará hasta que finalice la ejecución de Top.
Ejemplo --> top -n9 (Refrescará la información nueve veces y finalizará la ejecución de TOP)
Servicio de transferencia de archivos
El FTP se basa en el modelo cliente/servidor y permite la transferencia de ficheros tanto del servidor al cliente, como del cliente al servidor. Asimismo, permite que un cliente efectúe transferencias directas de un servidor a otro, con lo que se ahorra la necesidad de copiar
los ficheros del primer servidor al cliente y pasarlos después del cliente al segundo servidor.
El protocolo proporciona también operaciones para que el cliente pueda manipular el sistema de ficheros del servidor: borrar ficheros o cambiarles el nombre, crear y borrar directorios, listar sus contenidos, etc.
Uno de los objetivos principales de este protocolo consiste en permitir la interoperabilidad entre sistemas muy distintos, escondiendo los detalles de la estructura interna de los sistemas de ficheros locales y de la organización de los contenidos de los ficheros.
Otra variante a considerar sería SFTP pues la información de nuestras credenciales de usuario y contraseña están encriptadas y el proceso se realizaría con la implementación del servicio SSH.
Los clientes establecen una conexión TCP de control con el servidor (normalmente en el puerto 21 del servidor)
Sobre esta conexión, cliente y servidor se intercambian información de usuarios, contraseñas, nombres de ficheros, operaciones,…
En base a la negociación que se establece sobre la conexión de control se decide como subir/descargar los datos
Existen dos tipos de usuarios:
Usuarios FTP: aquellos que disponen de una cuenta en la máquina que ofrece el servicio FTP.
Usuarios anónimos: usuarios cuales quiera que, al conectarse al servidor FTP, sólo deben introducir una contraseña simbólica. Sólo tienen acceso a una parte limitada del sistema de archivos.
FTP admite dos modos de conexión del cliente. Estos modos se denominan activo y pasivo. Tanto en el modo Activo como en el modo Pasivo, el cliente establece una conexión con el servidor mediante el puerto 21, que establece el canal de control.
Modo activo
En modo Activo, el servidor siempre crea el canal de datos en su puerto 20, mientras que en el lado del cliente el canal de datos se asocia a un puerto aleatorio mayor que el 1024. Para ello, el cliente manda un comando PORT al servidor por el canal de control indicándole ese número de puerto, de manera que el servidor pueda abrirle una conexión de datos por donde se transferirán los archivos y los listados, en el puerto especificado.
Lo anterior tiene un grave problema de seguridad, y es que la máquina cliente debe estar dispuesta a aceptar cualquier conexión de entrada en un puerto superior al 1024, con los problemas que ello implica si tenemos el equipo conectado a una red insegura como Internet.

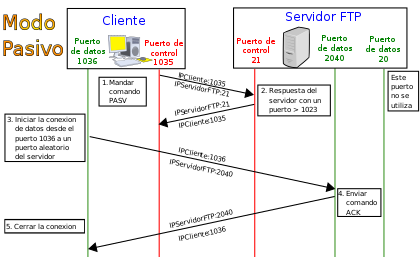
Modo pasivo
Cuando el cliente envía un comando PASV sobre el canal de control, el servidor FTP le indica por el canal de control, el puerto (mayor a 1023 del servidor. Ej:2040) al que debe conectarse el cliente. El cliente inicia una conexión desde el puerto siguiente al puerto de control (ej: 1036) hacia el puerto del servidor especificado anteriormente (ej: 2040).
Antes de cada nueva transferencia tanto en el modo Activo como en el Pasivo, el cliente debe enviar otra vez un comando de control y el servidor recibirá esa conexión de datos en un nuevo puerto aleatorio (si está en modo pasivo) o por el puerto 20
Existen dos tipos de transferencia de archivos:
tipo ascii : Adecuado para transferir archivos que sólo contengan caracteres imprimibles (archivos ASCII, no archivos resultantes de un procesador de texto), por ejemplo páginas HTML, pero no las imágenes que puedan contener.
tipo binario: Este tipo es usado cuando se trata de archivos comprimidos, ejecutables para PC, imágenes, archivos de audio...
los ficheros del primer servidor al cliente y pasarlos después del cliente al segundo servidor.
El protocolo proporciona también operaciones para que el cliente pueda manipular el sistema de ficheros del servidor: borrar ficheros o cambiarles el nombre, crear y borrar directorios, listar sus contenidos, etc.
Uno de los objetivos principales de este protocolo consiste en permitir la interoperabilidad entre sistemas muy distintos, escondiendo los detalles de la estructura interna de los sistemas de ficheros locales y de la organización de los contenidos de los ficheros.
Otra variante a considerar sería SFTP pues la información de nuestras credenciales de usuario y contraseña están encriptadas y el proceso se realizaría con la implementación del servicio SSH.
Los clientes establecen una conexión TCP de control con el servidor (normalmente en el puerto 21 del servidor)
Sobre esta conexión, cliente y servidor se intercambian información de usuarios, contraseñas, nombres de ficheros, operaciones,…
En base a la negociación que se establece sobre la conexión de control se decide como subir/descargar los datos
Existen dos tipos de usuarios:
Usuarios FTP: aquellos que disponen de una cuenta en la máquina que ofrece el servicio FTP.
Usuarios anónimos: usuarios cuales quiera que, al conectarse al servidor FTP, sólo deben introducir una contraseña simbólica. Sólo tienen acceso a una parte limitada del sistema de archivos.
FTP admite dos modos de conexión del cliente. Estos modos se denominan activo y pasivo. Tanto en el modo Activo como en el modo Pasivo, el cliente establece una conexión con el servidor mediante el puerto 21, que establece el canal de control.
Modo activo
En modo Activo, el servidor siempre crea el canal de datos en su puerto 20, mientras que en el lado del cliente el canal de datos se asocia a un puerto aleatorio mayor que el 1024. Para ello, el cliente manda un comando PORT al servidor por el canal de control indicándole ese número de puerto, de manera que el servidor pueda abrirle una conexión de datos por donde se transferirán los archivos y los listados, en el puerto especificado.
Lo anterior tiene un grave problema de seguridad, y es que la máquina cliente debe estar dispuesta a aceptar cualquier conexión de entrada en un puerto superior al 1024, con los problemas que ello implica si tenemos el equipo conectado a una red insegura como Internet.
Modo pasivo
Cuando el cliente envía un comando PASV sobre el canal de control, el servidor FTP le indica por el canal de control, el puerto (mayor a 1023 del servidor. Ej:2040) al que debe conectarse el cliente. El cliente inicia una conexión desde el puerto siguiente al puerto de control (ej: 1036) hacia el puerto del servidor especificado anteriormente (ej: 2040).
Antes de cada nueva transferencia tanto en el modo Activo como en el Pasivo, el cliente debe enviar otra vez un comando de control y el servidor recibirá esa conexión de datos en un nuevo puerto aleatorio (si está en modo pasivo) o por el puerto 20
Existen dos tipos de transferencia de archivos:
tipo ascii : Adecuado para transferir archivos que sólo contengan caracteres imprimibles (archivos ASCII, no archivos resultantes de un procesador de texto), por ejemplo páginas HTML, pero no las imágenes que puedan contener.
tipo binario: Este tipo es usado cuando se trata de archivos comprimidos, ejecutables para PC, imágenes, archivos de audio...
domingo, 13 de noviembre de 2011
Autenticaciones en Apache
Hemos visto que una manera de acceder a un sitio web de Apache es mediante autenticación contra un servidor LDAP. Ahora nos vamos a dedicar a investigar sobre otras formas de autentificación distintas a LDAP.
Así que nos limitaremos a describir cómo implementar autenticación básica y PAM. Cada módulo de autenticación tiene su forma particular de ser activado y gestionado, pero estas dos formas de autenticación servirán como base para hacerse una idea clara de cómo manejar el resto de las mismas.
Pasaremos directamente a ver cómo funcionan a base de actividades prácticas:
El primer paso es incluir las siguientes líneas en el fichero apache2.conf, que indicarán a Apache que se desea este tipo de autenticación sobre el directorio indicado.

Una de las cosas nuevas que tiene el contenido anterior es una referencia a un fichero authgroups. Este fichero debe contener un listado de usuarios que han sido creados expresamente para esta clase de autenticación (lo veremos a continuación) y que han sido distribuidos en una serie de grupos, que también aparecen en el mismo. Esto permite crear varias áreas de acceso en diversas partes de la web donde un mismo grupo pueda tener diferentes privilegios o bien sólo algunos puedan acceder a los contenidos.
Evidentemente, cuando se comprueben las credenciales de un usuario para conceder el acceso a un lugar protegido, dicho usuario debe pertenecer a uno de los grupos autorizados. La directiva del ejemplo anterior "Require group privado" hace que solo los usuarios de este grupo (que como veremos posteriormente serán alfa y beta) tengan acceso a este directorio vía web.
Antes de seguir deberemos de crear los usuarios y los grupos con los que vamos a trabajar en esta actividad (he creado 2 usuarios: “alfa” y “beta” pertenecientes a un grupo llamado “privado” y otro usuario “f1” perteneciente al grupo “otros”)
El contenido del fichero authgroups se puede crear simplemente con un editor de texto como el nano, y debe hacerse en la carpeta indicada anteriormente en el apache2.conf. El contenido es muy sencillo y debe seguir el patrón: , tal y como se ve a continuación:

Finalmente, debemos construir las password de los usuarios que se mencionan en el fichero de grupos. Esto se hace con la siguiente secuencia de comandos, invocando un comando htpasswd por cada usuario registrado. Al llamar a esta orden se solicitará por entrada estándar una clave para cada usuario:

Nos preguntara por el nombre del usuario que queramos que tenga acceso a nuestro directorio autentif_basic y solamente podremos entrar como usuarios “alfa” o “beta” porque son los que pertenecen al grupo privado (todo ello declarado en el archivo authgroups anteriormente). He comprobado que el usuario “f1” al pertenecer al grupo “otros” no tiene acceso al interior de la carpeta con su contraseña y efectivamente no tiene acceso de tal forma que mediante esta autentificación podremos hacer que accedan a una determinada carpeta solo los usuarios que declaremos en el archivo anterior (habiendo creado previamente los usuarios y los grupos en el sistema claro está…)

Comprobamos el acceso con los usuarios alfa y beta y vemos que entran perfectamente a la carpeta
En caso de que le demos a cancelar como será el caso del usuario f1 que es imposible que acceda al sistema, cuando nos solicita el usuario y la contraseña y pulsemos en la opción cancelar nos saldrá la siguiente información

El segundo método que vamos a tocar usa PAM, el propio sistema de autenticación de la máquina donde está instalado nuestro servidor de Apache.
Usaremos para ello el módulo mod_auth_pam y lo primero que tenemos que hacer es instalarlo:
“sudo apt-get install libapache2-mod-auth-pam”
En el fichero apache2.conf vamos a introducir la siguiente información referente al directorio “/var/www/contacto”

Si en este caso la directiva usada fuese Require valid-user se permitiría el acceso a cualquier usuario con cuenta en la máquina. Después de esto hay que reiniciar el servicio apache2
Ahora hay que añadir el usuario www-data (el que usa apache) al grupo shadow para que pueda verificar las contraseñas:
“usermod -a -G shadow www-data”
Vamos a hacer un enlace, el motivo de que esto sea necesario es debido a que apache pretende leer del archivo /etc/pam.d/http mientras que el módulo de autenticación ha creado el archivo /etc/pam.d/apache2. El módulo auth_pam hace años que no está soportado y por eso lo hacemos el enlace de la siguiente manera:
“ln -s /etc/pam.d/apache2 /etc/pam.d/httpd”
Y con esto está todo listo. Ahora vamos al navegador a probar la nueva configuración con un usuario “pacopepe” que he creado para esta autenticación

Nos logueamos como pacopepe y vemos que funciona (él será el único usuario del sistema que podrá entrar debido a que solamente declaramos al usuario pacopepe para entrar en el apache2.conf)

Así que nos limitaremos a describir cómo implementar autenticación básica y PAM. Cada módulo de autenticación tiene su forma particular de ser activado y gestionado, pero estas dos formas de autenticación servirán como base para hacerse una idea clara de cómo manejar el resto de las mismas.
Pasaremos directamente a ver cómo funcionan a base de actividades prácticas:
Autenticación Básica con Apache
El primer paso es incluir las siguientes líneas en el fichero apache2.conf, que indicarán a Apache que se desea este tipo de autenticación sobre el directorio indicado.

Una de las cosas nuevas que tiene el contenido anterior es una referencia a un fichero authgroups. Este fichero debe contener un listado de usuarios que han sido creados expresamente para esta clase de autenticación (lo veremos a continuación) y que han sido distribuidos en una serie de grupos, que también aparecen en el mismo. Esto permite crear varias áreas de acceso en diversas partes de la web donde un mismo grupo pueda tener diferentes privilegios o bien sólo algunos puedan acceder a los contenidos.
Evidentemente, cuando se comprueben las credenciales de un usuario para conceder el acceso a un lugar protegido, dicho usuario debe pertenecer a uno de los grupos autorizados. La directiva del ejemplo anterior "Require group privado" hace que solo los usuarios de este grupo (que como veremos posteriormente serán alfa y beta) tengan acceso a este directorio vía web.
Antes de seguir deberemos de crear los usuarios y los grupos con los que vamos a trabajar en esta actividad (he creado 2 usuarios: “alfa” y “beta” pertenecientes a un grupo llamado “privado” y otro usuario “f1” perteneciente al grupo “otros”)
El contenido del fichero authgroups se puede crear simplemente con un editor de texto como el nano, y debe hacerse en la carpeta indicada anteriormente en el apache2.conf. El contenido es muy sencillo y debe seguir el patrón

Finalmente, debemos construir las password de los usuarios que se mencionan en el fichero de grupos. Esto se hace con la siguiente secuencia de comandos, invocando un comando htpasswd por cada usuario registrado. Al llamar a esta orden se solicitará por entrada estándar una clave para cada usuario:
- touch /etc/apache2/authusers
- htpasswd /etc/apache2/authusers alfa
- htpasswd /etc/apache2/authusers beta
- htpasswd /etc/apache2/authusers f1

Nos preguntara por el nombre del usuario que queramos que tenga acceso a nuestro directorio autentif_basic y solamente podremos entrar como usuarios “alfa” o “beta” porque son los que pertenecen al grupo privado (todo ello declarado en el archivo authgroups anteriormente). He comprobado que el usuario “f1” al pertenecer al grupo “otros” no tiene acceso al interior de la carpeta con su contraseña y efectivamente no tiene acceso de tal forma que mediante esta autentificación podremos hacer que accedan a una determinada carpeta solo los usuarios que declaremos en el archivo anterior (habiendo creado previamente los usuarios y los grupos en el sistema claro está…)

Comprobamos el acceso con los usuarios alfa y beta y vemos que entran perfectamente a la carpeta
En caso de que le demos a cancelar como será el caso del usuario f1 que es imposible que acceda al sistema, cuando nos solicita el usuario y la contraseña y pulsemos en la opción cancelar nos saldrá la siguiente información

Autenticación PAM con Apache
Usaremos para ello el módulo mod_auth_pam y lo primero que tenemos que hacer es instalarlo:
“sudo apt-get install libapache2-mod-auth-pam”
En el fichero apache2.conf vamos a introducir la siguiente información referente al directorio “/var/www/contacto”

Si en este caso la directiva usada fuese Require valid-user se permitiría el acceso a cualquier usuario con cuenta en la máquina. Después de esto hay que reiniciar el servicio apache2
Ahora hay que añadir el usuario www-data (el que usa apache) al grupo shadow para que pueda verificar las contraseñas:
“usermod -a -G shadow www-data”
Vamos a hacer un enlace, el motivo de que esto sea necesario es debido a que apache pretende leer del archivo /etc/pam.d/http mientras que el módulo de autenticación ha creado el archivo /etc/pam.d/apache2. El módulo auth_pam hace años que no está soportado y por eso lo hacemos el enlace de la siguiente manera:
“ln -s /etc/pam.d/apache2 /etc/pam.d/httpd”
Y con esto está todo listo. Ahora vamos al navegador a probar la nueva configuración con un usuario “pacopepe” que he creado para esta autenticación

Nos logueamos como pacopepe y vemos que funciona (él será el único usuario del sistema que podrá entrar debido a que solamente declaramos al usuario pacopepe para entrar en el apache2.conf)

sábado, 5 de noviembre de 2011
Servicios del Sistema
Un servicio es un programa que está ejecutándose indefinidamente para atender a peticiones de otros programas o del usuario. Por defecto W2003, ejecuta automáticamente muchos servicios (necesarios o no) que consumen más memoria que la necesaria para las funciones que está desempeñando el sistema
Para ejecutar la utilidad Servicios hay que hacerlo habiendo iniciado sesión como administrador e irnos a Inicio->Programas->Herramientas Administrativas->Servicios.
Existen tres opciones a la hora de elegir el tipo de inicio de un servicio que esté disponible en el sistema:
1. Automático: el servicio se inicia automáticamente mientras se carga el sistema operativo (Windows 2003). Esta opción puede incrementar el tiempo de inicio del sistema, así como el consumo de recursos, mientras que el servicio igual no es necesario.
2. Manual: el servicio no se inicia de forma predeterminada tras la carga del sistema operativo, en cambio pude ser iniciado - manualmente - en cualquier instante.
3. Deshabilitado: obliga al administrador a tener que habilitarlo antes de poder ejecutarlo.
Pinchando en propiedades (de cualquier servicio) y posteriormente en Tipo de inicio podemos definir el servicio para que inicie de una manera o de otra.
Las relaciones de dependencia entre los servicios implican que a la hora de parar servicios, todos aquellos que dependan de él se verán afectados también y así sucesivamente, corriendo el peligro de dejar el sistema en un estado no utilizable.
Para saber qué servicios dependen de que otros, en la ficha de Propiedades del servicio, elige la lengüeta Dependencias.
En propiedades eligiendo la lengüeta Recuperación podemos definir qué hacer cuando se produce un fallo o parada del servicio.
Las acciones posibles a tomar son:
Ø No realizar ninguna acción
Ø Reiniciar el servicio: el sistema intentará reiniciar el servicio si este falló. Se puede definir el periodo de tiempo en minutos en que lo volverá a intentar
Ø Ejecutar un archivo: tenemos la posibilidad de ejecutar un archivo de comandos para tomar de una forma más granular las acciones adecuadas.
Ø Reiniciar el equipo: si es un servicio importante y no hay forma de levantarlo.
Puede suceder que al haber deshabilitado un servicio que era necesario para la carga del sistema operativo Windows 2003 o para el buen funcionamiento del sistema, nos encontremos con la desagradable situación de que la utilidad de Servicios no nos permite devolver el estado a un servicio concreto. Una opción para arreglar esto es editar la subclave del registro HKLM\SYSTEM\CurrentControlSet\Services
Es aquí donde se almacena el valor de tipo de inicio para cada servicio. Lo que hay que hacere es seleccionar el servicio apropiado y en el panel de la derecha cambiar el valor de la clave Start de tipo. Un valor DWORD hexadecimal o decimal determina el tipo de inicio del servicio. Los valores posibles de esta clave son:
- Un valor 2 significa un tipo de inicio Automático
-Un valor 3 significa un tipo de inicio Manual.
-Un valor 4 significa que el servicio está deshabilitado
lunes, 24 de octubre de 2011
Administración de Políticas de Grupo Windows 2003
Las políticas de grupo permiten establecer de forma centralizada múltiples aspectos de la configuración que reciben los usuarios cuando se conectan a una máquina del dominio.
Cuando hay muchos equipos que administrar en un dominio, resultaría incómodo tener que establecer este comportamiento uno por uno. Por este motivo, las políticas de grupo se han integrado dentro de la administración del Directorio Activo como una herramienta de configuración centralizada en dominios Windows 2003.
Las políticas se especifican mediante objetos de directorio denominados Objetos de Política de Grupo (Group Policy Objects), o simplemente GPOs. Un GPO es un objeto que incluye como atributos cada una de las políticas (también denominadas directivas) que puede establecerse en Windows Server 2003 para equipos y usuarios. Los GPOs se crean y posteriormente se vinculan a distintos contenedores del Directorio Activo (sitios, dominios y unidades organizativas), de forma que los usuarios y equipos que se ubican dentro de estos contenedores reciben los parámetros de configuración establecidos en dichos GPOs.
Dentro de cada GPO, las políticas se organizan jerárquicamente en un árbol temático en el que existen dos nodos principales que separan las configuraciones para equipos y para usuarios.
Las políticas de grupo son heredables y acumulativas. Eso quiere decir que, desde el punto de vista de un equipo o de un usuario concreto, la lista de GPOs que les afecta depende de su ubicación en Directorio Activo.
Resulta necesario que exista un orden de aplicación concreto y conocido, de forma que se sepa finalmente qué política afectarán a cada usuario y equipo. Este orden es el siguiente:
1. Se aplica la política de grupo local del equipo (denominada Local Group Policy
Object, o LGPO).
2. Se aplican los GPOs vinculados a sitios.
3. Se aplican los GPOs vinculados a dominios.
4. Se aplican los GPOs vinculados a unidades organizativas de primer nivel. En su caso, posteriormente se aplicarían GPOs vinculados a unidades de segundo nivel, de tercer nivel, etc.
Este orden de aplicación decide la prioridad entre los GPOs, puesto que una política que se aplica más tarde prevalece sobre otras establecidas anteriormente (las sobrescribe).
Este comportamiento puede ser refinado mediante los siguientes dos parámetros:
1. Forzado (Enforced)
2. Bloquear herencia de directivas
Como todos los objetos del Directorio Activo, los GPOs poseen listas de control de acceso (o DACLs). En general, estas DACLs establecen qué usuarios y grupos pueden leer, escribir, administrar, etc., dichos objetos. En el caso concreto de los GPOs, esta asociación de permisos a grupos de usuarios (o grupos de seguridad) permite filtrar el ámbito de aplicación de un GPO y delegar su administración.
Es posible delegar la administración de GPOs a otros usuarios y grupos. En realidad, la administración de un GPO consta de dos actividades distintas y complementarias, que pueden delegarse independientemente:
-Creación de un GPO.
-Vinculación de un GPO a un contenedor.
Las principales políticas incluidas en un GPO
-Configuración de Software
-Configuración de Windows
-Plantillas Administrativas
Las configuraciones de seguridad que se pueden establecer son las siguientes:
-Políticas de cuentas
-Políticas locales
-Registro de eventos
Mediante este apartado se puede asignar y/o publicar aplicaciones a equipos o a usuarios en el dominio:
1. Asignar una aplicación significa que los usuarios que la necesitan la tienen disponible
en su escritorio sin necesidad de que un administrador la instale.
2. Publicar una aplicación a un equipo o usuario le da la oportunidad al usuario
de instalar dicha aplicación bajo demanda (a voluntad), pero no se realiza ninguna
acción automática en el equipo
Se pueden asignar scripts a equipos o usuarios. En concreto, existen cuatro tipos de scripts principales:
-Inicio (equipo)
-Apagado (equipo)
-Inicio de sesión (usuario)
-Cierre de sesión (usuario)
Existe también una política denominada redireccionamiento de carpetas.
Este grupo de políticas permite redirigir la ubicación local predefinida de ciertas carpetas particulares de cada usuario (como "Mis Documentos" o el menú de inicio) a otra ubicación, bien sea en la misma máquina o en una unidad de red.
Existen otras políticas como el mantenimiento de internet explorer y los servicios de instalación remota.
Suscribirse a:
Entradas (Atom)